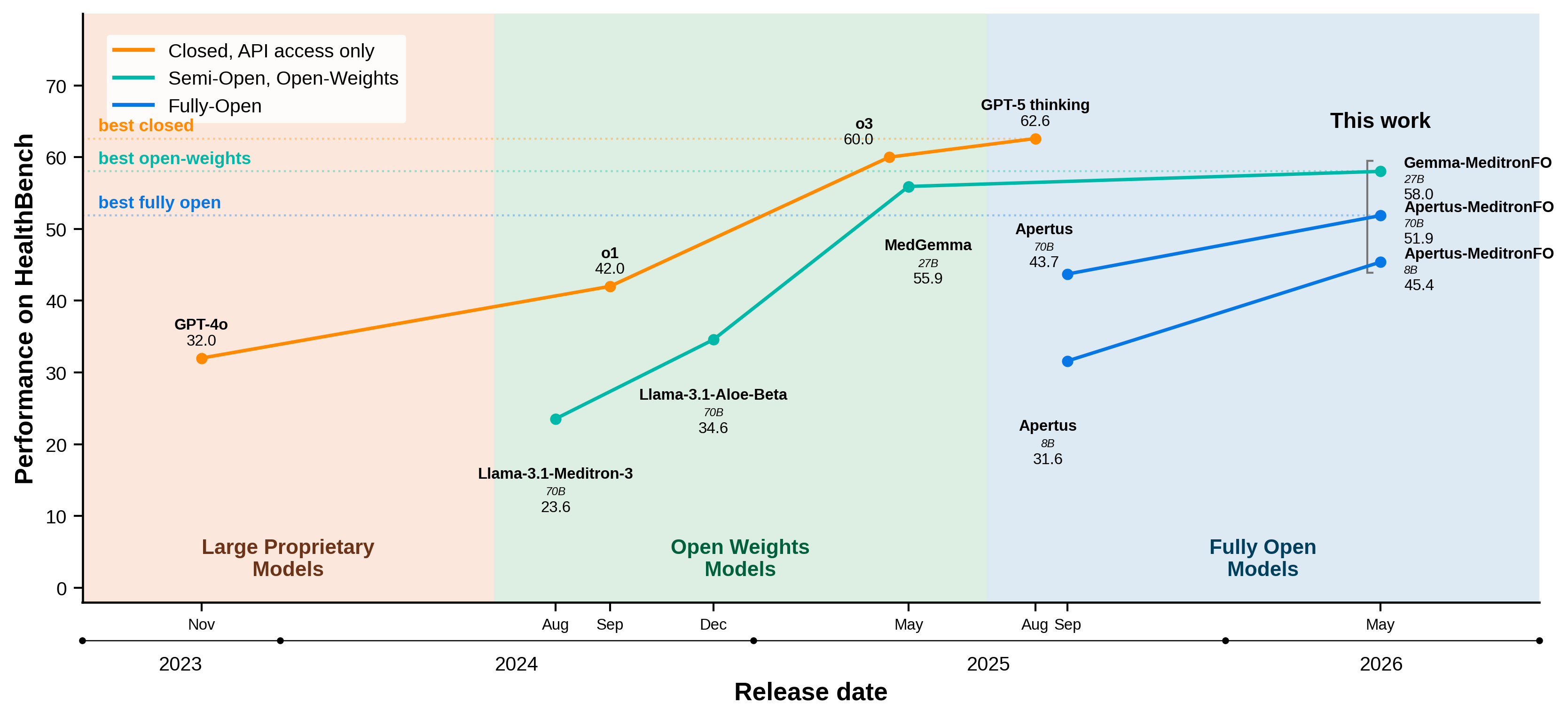
TL;DR — Most "open" medical AI models hide the data and recipe they were trained on, so no one can audit what they actually learned. We built the first medical AI where every step is open and it still beats leading partially open systems.
Clinical decision support systems (CDSS) require scrutable, auditable pipelines that enable rigorous, reproducible validation. Yet current LLM-based CDSS (LLM-CDSS) remain largely opaque. Most "open" models are open-weight only, releasing parameters while withholding the data provenance, curation procedures, and generation pipelines that determine model behavior. Fully Open (FO) models, which expose the complete training stack end-to-end, do not currently exist in medicine. We introduce Fully Open Meditron, the first fully open pipeline for building LLM-CDSS, comprising a clinician-audited training corpus, a reproducible data construction and training framework, and a use-aligned evaluation protocol. The corpus unifies eight public medical QA datasets into a normalized conversational format and expands coverage with three clinician-vetted synthetic extensions: exam-style QA, guideline-grounded QA derived from 46,469 clinical practice guidelines, and clinical vignettes. We apply the recipe to five FO base models. Apertus-70B-MeditronFO improves +6.6 points over its base (47.2% to 53.8%) on aggregate medical benchmarks, establishing a new FO SoTA for LLM-CDSS, and Gemma-3-27B-MeditronFO surpasses MedGemma on HealthBench (58% vs 55.9%). These results show that fully open pipelines can achieve state-of-the-art domain-specific performance without sacrificing auditability or reproducibility.
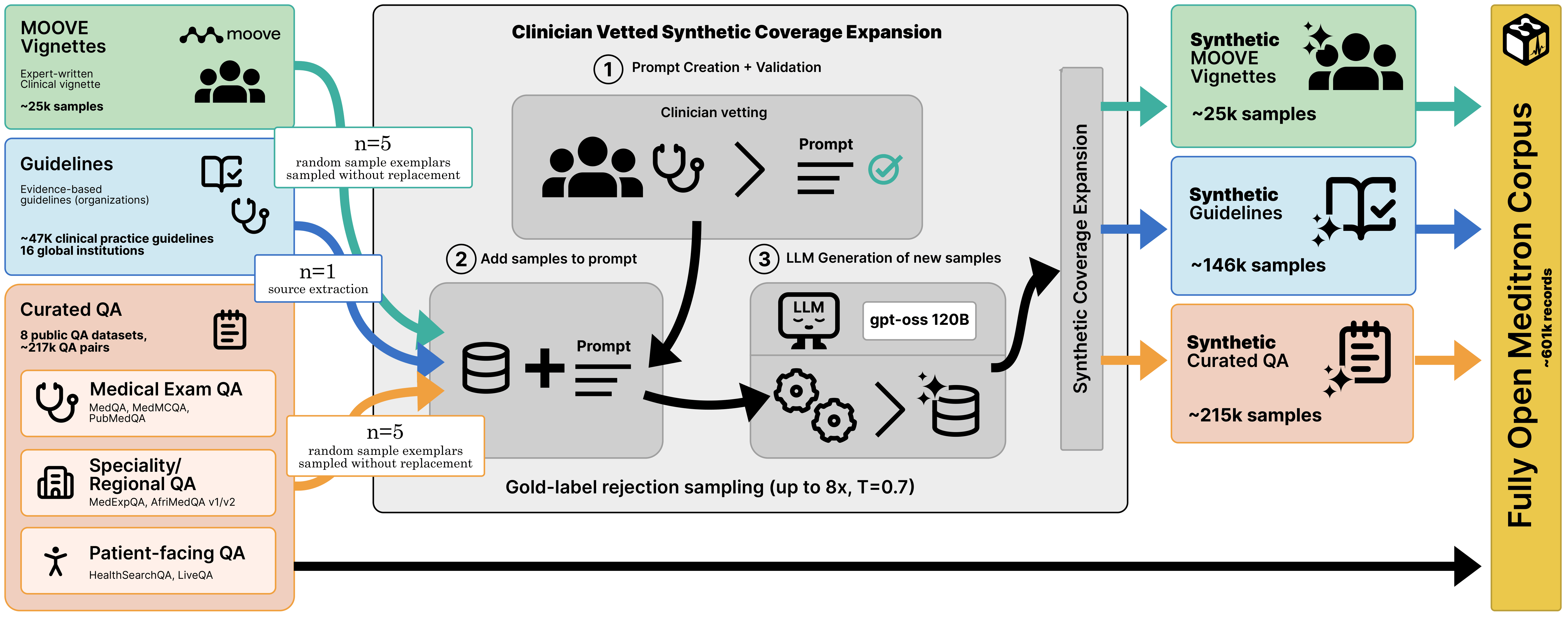
Our release includes:
We argue that clinically competitive medical specialization can be achieved using reproducible, auditable pipelines rather than opaque adaptation procedures, providing a reusable foundation for training and evaluating future fully open medical models.
| Model | MedMCQA | MedQA | PubMedQA | MedXpertQA | HealthBench | Avg | Gain |
|---|---|---|---|---|---|---|---|
| Fully open base | |||||||
| Apertus-70B-Instruct | 52.43 | 60.64 | 66.80 | 12.33 | 43.72 | 47.18±0.84 | – |
| + Fully Open Meditron | 56.32 | 68.58 | 75.20 | 16.90 | 51.86 | 53.77±0.86 | 6.59 |
| OLMo-2-32B-SFT | 59.10 | 66.22 | 72.00 | 13.02 | 31.03 | 51.52±0.81 | – |
| + Fully Open Meditron | 57.83 | 69.44 | 76.60 | 17.96 | 44.00 | 53.17±0.85 | 1.65 |
| EuroLLM-22B-Instruct | 54.94 | 66.61 | 73.60 | 14.61 | 43.72 | 50.70±0.84 | – |
| + Fully Open Meditron | 54.79 | 63.16 | 78.00 | 14.61 | 46.22 | 51.36±0.84 | 0.66 |
| Small fully open base | |||||||
| Apertus-8B-Instruct | 45.80 | 51.14 | 37.60 | 11.71 | 31.61 | 35.57±0.76 | – |
| + Fully Open Meditron | 48.74 | 58.44 | 75.60 | 13.67 | 45.38 | 48.37±0.84 | 12.80 |
| EuroLLM-9B-Instruct | 37.84 | 48.55 | 40.00 | 10.33 | 23.00 | 31.94±0.72 | – |
| + Fully Open Meditron | 46.98 | 49.73 | 67.40 | 11.63 | 37.53 | 42.65±0.81 | 10.71 |
| Open-access base | |||||||
| gemma-3-27b-it | 62.75 | 76.20 | 74.60 | 16.69 | 57.49 | 57.55±0.83 | – |
| + Fully Open Meditron | 63.71 | 77.61 | 75.80 | 18.00 | 58.02 | 58.63±0.83 | 1.08 |
| MedGemma-27B | 66.44 | 86.10 | 73.00 | 21.88 | 55.92 | 60.67±0.81 | 3.12 |
Medical benchmark accuracy (%). Best within partition in bold; best fully open underlined. HealthBench uses the full benchmark with Qwen3-235B-A22B as judge.
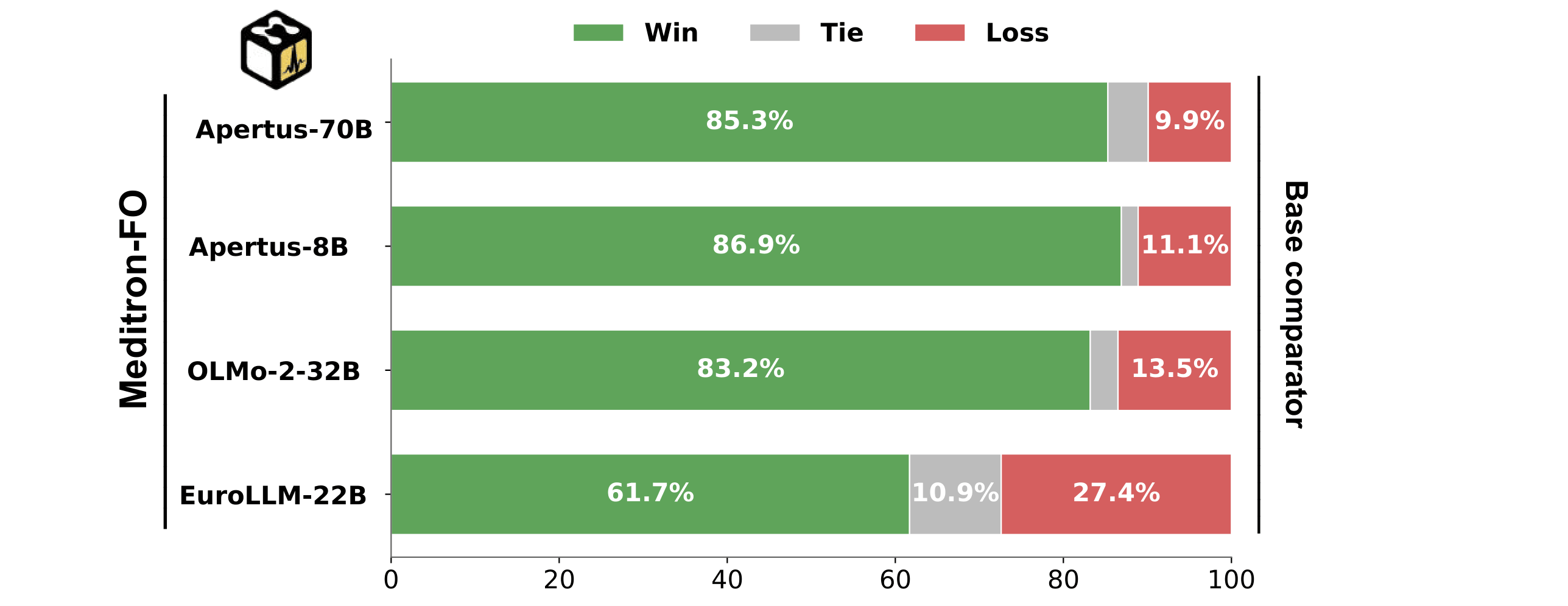
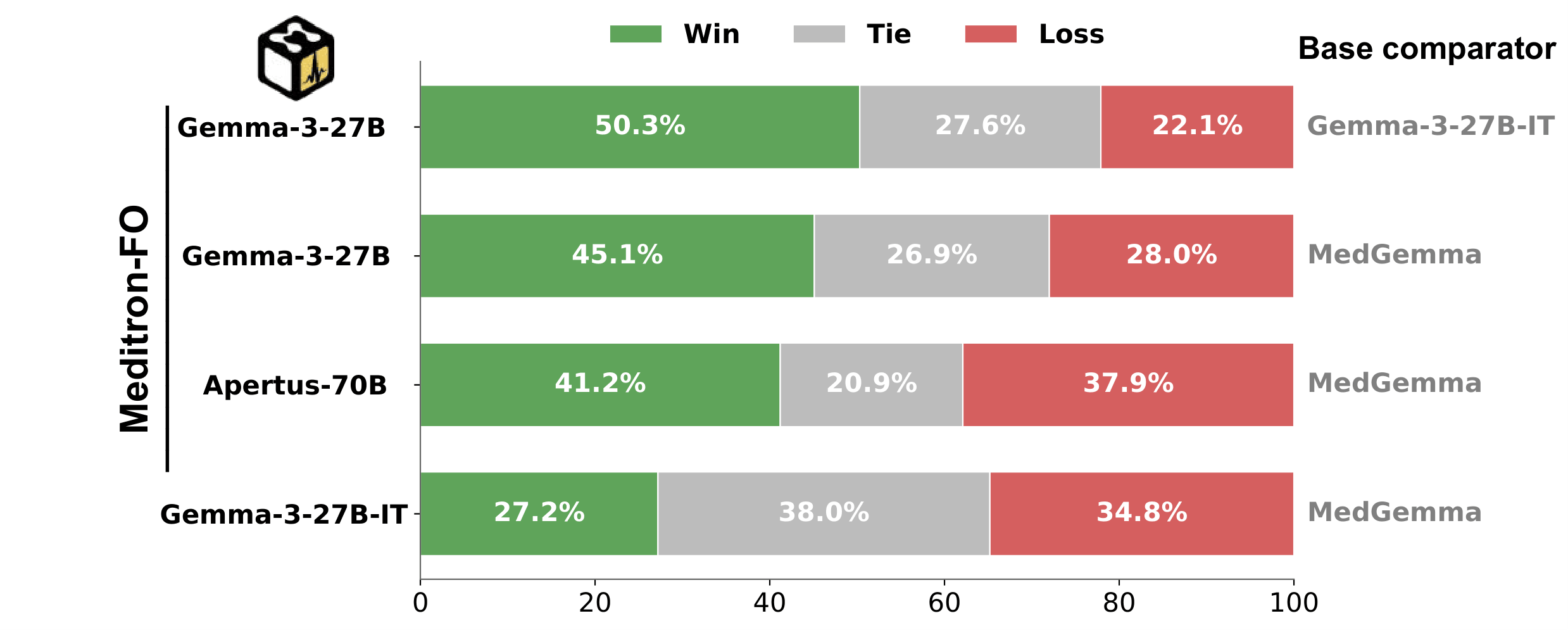
Auto-MOOVE pairwise preference results: every MeditronFO model is preferred over its corresponding base (left), and Gemma-3-27B-MeditronFO is preferred over MedGemma (right).
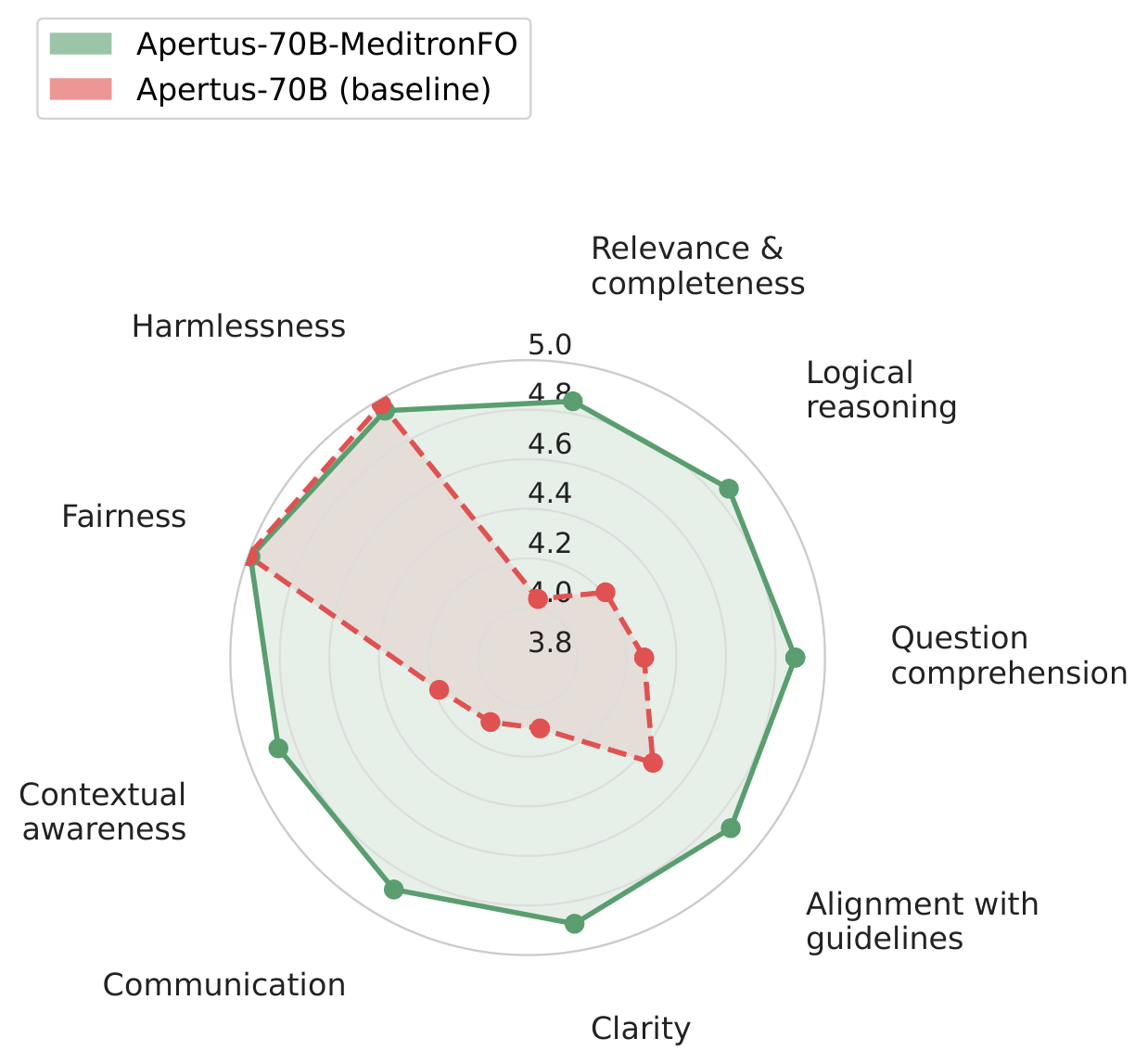
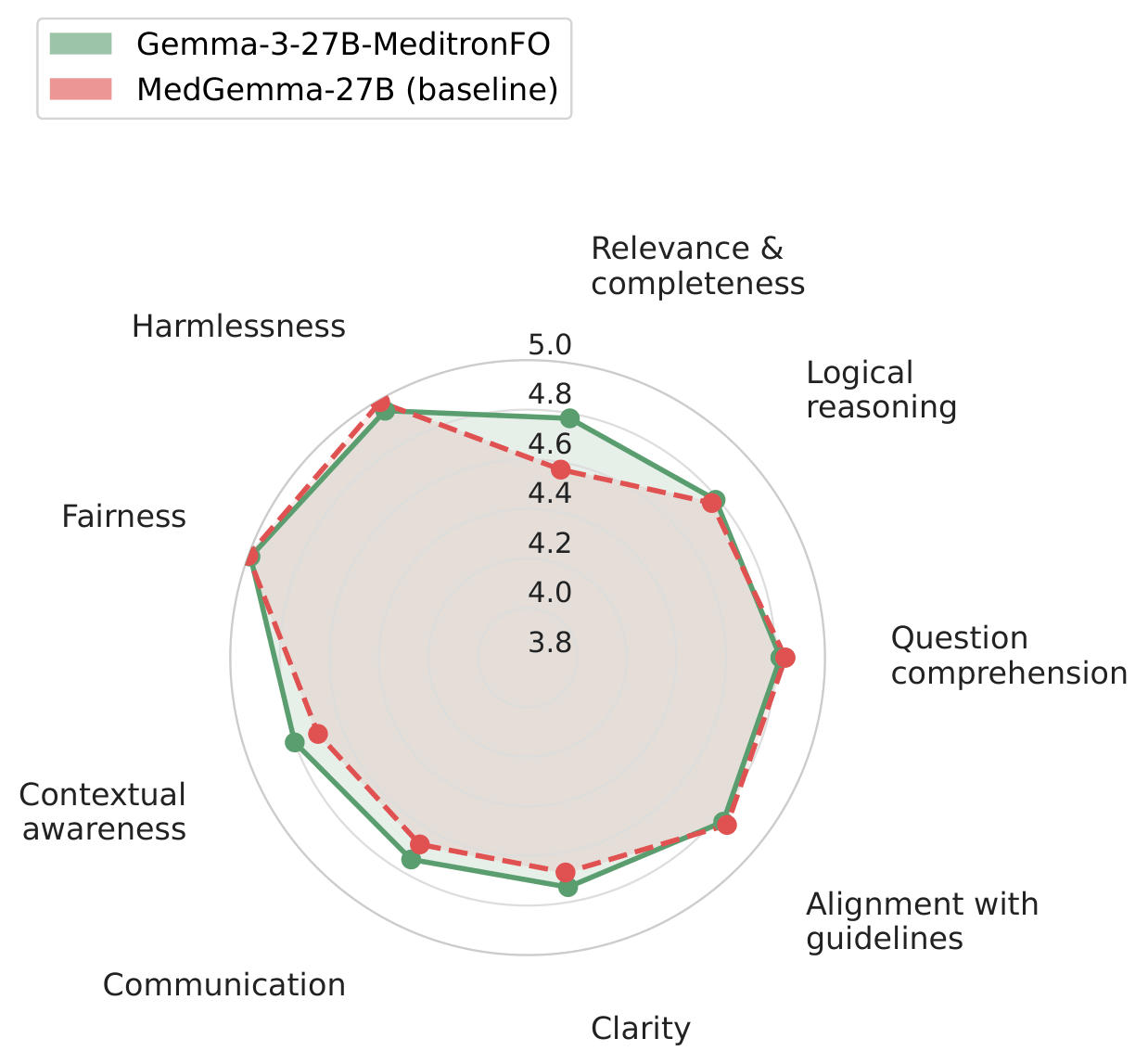
Per-criterion Likert profiles show improvements across all nine clinical evaluation dimensions.
| Model | Base | Base model openness | Medical adaptation openness | License | |||||
|---|---|---|---|---|---|---|---|---|---|
| Data | Code | Weights | Data | Synth | Code | Weights | |||
| Closed | |||||||||
| Med-Gemini | Gemini | R | |||||||
| Open Weights | |||||||||
| BioMistral | Mistral | O | |||||||
| Meditron-70B | Llama 2 | IC | |||||||
| Meditron-3 | Llama 3.1 | IC | |||||||
| Aloe Beta | Llama 3.1 | R | |||||||
| MedGemma-27B | Gemma-3-27B-it | C | |||||||
| Partially Open | |||||||||
| Gemma-3-27B-MeditronFO | Gemma-3-27B-it | IC | |||||||
| Fully Open | |||||||||
| Apertus-70B-MeditronFO | Apertus-70B | O | |||||||
| OLMo-2-32B-MeditronFO | OLMo-2-32B | O | |||||||
| EuroLLM-22B-MeditronFO | EuroLLM-22B | O | |||||||
Openness across medical LLMs. MeditronFO is the first family to satisfy every dimension end-to-end. License: O = permissive open, C = community/commercial with restrictions, IC = inherited base-model license (adaptation permissively released), R = restrictive/research-only/proprietary.
@article{theimerlienhard2026fullyopenmeditron,
title={Fully Open Meditron: An Auditable Pipeline for Clinical LLMs},
author={Theimer-Lienhard, Xavier and El-Amin, Mushtaha and Elhassan, Fay and Vaidya, Sahaj and Cartier-Negadi, Victor and Sasu, David and Klein, Lars and Hartley, Mary-Anne},
journal={arXiv preprint arXiv:2605.16215},
year={2026},
url={https://arxiv.org/abs/2605.16215}
}